
목록PYTHON (59)
도찐개찐
머신러닝으로 타이타닉 생존자 예측하기 다양한 머신러닝 알고리즘을 이용해서 교차검증 방식으로 모델을 훈련시키고 예측 정확도를 통해 평가해 봄 import numpy as np import pandas as pd import matplotlib.pyplot as plt import sklearn from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_score from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import Rando..
훈련과 테스트 데이터 머신러닝 모델을 만들기 위해서 데이터집합이 필요 과적합을 방지하기 위해 데이터를 훈련/테스트 데이터로 나누고 교차검증 방식으로 모델을 만들어 성능을 평가함 훈련데이터 : 모델 추정및 학습이 목적 테스트데이터 : 모델 성능 평가가 목적 분할 비율은 7:3 또는 8:2로 설정 import numpy as np import pandas as pd import matplotlib.pyplot as plt import sklearn train/test 분할 없이 분석하는 경우 from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accurac..
 [머신러닝] 02. sklearn
[머신러닝] 02. sklearn
sklearn 파이썬 기반 쉽고 효율적인 머신러닝 라이브러리 제공 머신러닝을 위한 다양한 알고리즘 제공 데이터셋, 데이터전처리, 지도/비지도학습, 모델 선택/평가 등을 위한 모듈 제공 scikit-learn.org # !pip install scikit-learn import numpy as np import pandas as pd import matplotlib.pyplot as plt import sklearn sklearn.__version__ '1.1.3' scikit-learn에서 제공하는 데이터셋 확인 load : 내장된 데이터셋 불러옴 fetch : 인터넷을 통해 내려받는 대량 데이터 make : 확률분포에 근거해서 생성하는 가상 데이터 from sklearn.datasets import l..
인공지능의 정의 인간의 지능을 기계로 구현하는 모든 형태 인공지능의 범위 인공지능 > 머신러닝 > 딥러닝 인공지능 구현방식 초기에는 지식전달방식으로 구현 개발자가 기계에게 일반적인 규칙을 알려줌 심한 변환의 양상에는 잘 대처하지 못함 기호주의(rule-based) 후기에는 데이터중심으로 구현 데이터를 중심으로 기계가 학습(규칙/패턴인식)한 뒤 새로운 데이터를 통해 예측/분류함 훈련을 위한 많은 양질의 데이터가 필요 연결주의(신경망이용) 머신러닝 컴퓨터가 경험을 통해 학습할수 있도록 프로그래밍하되 세세하게 프로그래밍 해야하는 번거로움에서 벗어나게 하는 것 머신러닝 알고리즘 지도학습 : 데이터와 레이블(정답)을 통해 훈련 수행 분류 : 범주형데이터, 이진분류, 다항분류 ex) 개,고양이 사진 분류, 스팸분류..
 [데이터분석] 13. 다중회귀분석
[데이터분석] 13. 다중회귀분석
import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl import seaborn as sns from sklearn.datasets import load_boston from sklearn.datasets import fetch_california_housing from statsmodels.formula.api import ols fontpath = '/home/bigdata/py39/lib/python3.9/site-packages/matplotlib/mpl-data/fonts/ttf/NanumGothic.ttf' fname = mpl.font_manager.FontProperties..
 [데이터분석] 12. 회귀분석
[데이터분석] 12. 회귀분석
회귀분석 상관분석은 변수들이 얼마나 밀접한 관계를 가지고 있는지 분석하는 통계적 기법 한편, 회귀분석은 (상관분석 + 예측)하는 통계적 기법 수량형 값을 예측하는데 주로 사용되는 통계적 모형 즉, 두 변수간의 선형(직선)관계를 식으로 표현하고 독립변수 $x$가 주어지면 종속변수$y$의 값이 얼마인지 추정 독립변수와 종속변수 사이의 관계를 선형방정식으로 나타낸 것을 회귀방정식이라 함 $ \hat y = ax + b + \epsilon $ $a$ : 기울기 $b$ : 절편 $\epsilon$ : 오차, 잡음(noise) 회귀직선을 그릴때는 최소제곱법 이라는 수학적 기법을 이용하는데, 이는 두 변수의 선형관계를 계량화 한 것임 $$ a = \frac{\sum(x_i - \bar x)(y_i - \bar y)}..
 [데이터분석] 11. 상관분석
[데이터분석] 11. 상관분석
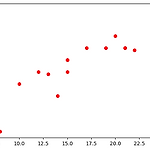
상관분석 두 변수 x, y가 있을때 두 변수가 서로 어떤 관계에 있는지 분석하는 과정 보통 2개의 등간/비율 척도 변수를 분석할때 우선적으로 산점도를 그려 변수간의 관계를 시각화 한 후 상관계수를 계산 변수들 관계 예 키x가 클수록 몸무게y도 증가하는가? 교육을 많이 받으면 수입도 증가하는가? 광고를 많이 하면 판매량이 증가하는가? 운동을 많이 하면 몸무게는 감소하는가? 담배를 줄이면 심혈관 질병 발생비율은 낮아지는가? 두 변수 정의 : 독립변수, 종속변수 독립변수 : 종속변수를 추정하거나 예측하는데 토대를 제공 (원인/설명 변수) 종속변수 : 예측되거나 추정되는 변수, 독립변수의 특정값에 대한 결과를 의미 (결과/반응 변수) 독립변수와 종속변수는 인과관계를 가질 가능성이 높음 (원인-결과 관계) 즉, ..
 [데이터시각화] 10. 다중그래프
[데이터시각화] 10. 다중그래프
다중 그래프 그리기 subplot(행, 열, 번호) import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns x = [1,2,3,4] y = [2,3,5,10] 수평 다중 그래프 plt.subplot(1, 2, 1) # 1행 2열 영역중 1행 1열 영역 plt.plot(x, y, 'r') plt.subplot(1, 2, 2) # 1행 2열 영역중 1행 2열 영역 plt.plot(x, y, 'b--') plt.tight_layout() 수직 다중 그래프 plt.subplot(2, 1, 1) # 2행 1열 영역중 1행 1열 영역 plt.plot(x, y, 'r--') plt.subplot(2, 1, ..