
도찐개찐
[머신러닝] 16. 랜덤 포레스트 본문
랜덤포레스트
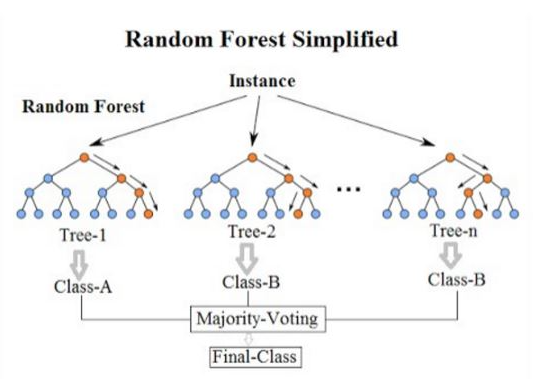
- 앙상블 학습 알고리즘 중 대표적인 학습 알고리즘
- 여러 개의 의사결정나무들을 생성한 다음,
- 각 개별 트리의 예측값들 중에서 가장 많이 선택된 클래스로 예측하는 알고리즘
- 물론, 배깅분류기에 의사결정트리를 넣는 대신 결정트리에 최적화되어 있는 포레스트분류기를 사용
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsfrom sklearn.model_selection import train_test_split
from sklearn.ensemble import VotingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score, f1_score
from sklearn.metrics import recall_score, precision_score
from sklearn.metrics import roc_curve, roc_auc_score테스트용 데이터 생성 및 분할
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=350, centers=4,
random_state=0, cluster_std=1.0)
plt.scatter(X[:,0], X[:,1], c=y, s=55)
plt.show()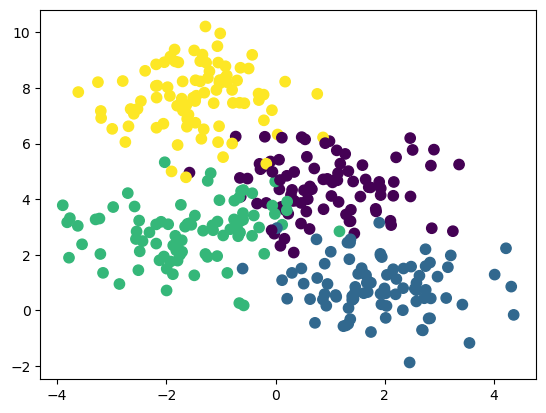
X_train, X_test, y_train, y_test = \
train_test_split(X, y, train_size=0.7,
stratify=y, random_state=2211211235)랜덤 포레스트 분류
# criterion: 정보 혼잡도 알고리즘 지정
rfclf = RandomForestClassifier(n_estimators=100, n_jobs=-1,
oob_score=True, criterion='entropy')
rfclf.fit(X_train, y_train)RandomForestClassifier(criterion='entropy', n_jobs=-1, oob_score=True)On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestClassifier(criterion='entropy', n_jobs=-1, oob_score=True)rfclf.oob_score_0.9016393442622951pred = rfclf.predict(X_test)
accuracy_score(y_test, pred)0.9150943396226415결정 영역 시각화
from mlxtend.plotting import plot_decision_regions
plot_decision_regions(X_train, y_train, rfclf)
특성 중요도
- 랜덤포레스트 분류기의 장점은 특성의 중요도를 측정할 수 있음
- 어떤 특성이 불순도를 낮추는지 확인하여 중요도를 측정
- feature_importances_를 이용해서 중요도 출력가능
과일, 채소 구분하기
- KNN 알고리즘을 이용해서 당도, 아삭함을 기준으로 과일인지 채소인지 구분
- 당도가 6, 아삭함이 4 인 토마토는 채소인가 과일인가?
fresh = pd.read_csv('../data/fresh.csv', encoding='cp949')fresh.head(3)| 이름 | 단맛 | 아삭거림 | 범주 | |
|---|---|---|---|---|
| 0 | 포도 | 8 | 5 | 과일 |
| 1 | 생선 | 2 | 2 | 단백질 |
| 2 | 당근 | 6 | 10 | 채소 |
fresh.columns = ['name', 'sweet', 'crunky', 'class']
# plt.scatter(fresh.단맛, fresh.아삭거림)fresh['class'] = fresh['class'].map({'과일': 0, '단백질': 1, '채소': 2})
fresh| name | sweet | crunky | class | |
|---|---|---|---|---|
| 0 | 포도 | 8 | 5 | 0 |
| 1 | 생선 | 2 | 2 | 1 |
| 2 | 당근 | 6 | 10 | 2 |
| 3 | 오렌지 | 7 | 3 | 0 |
| 4 | 샐러리 | 3 | 8 | 2 |
| 5 | 치즈 | 1 | 1 | 1 |
| 6 | 오이 | 2 | 8 | 2 |
| 7 | 사과 | 10 | 9 | 0 |
| 8 | 베이컨 | 1 | 4 | 1 |
| 9 | 바나나 | 10 | 1 | 0 |
| 10 | 콩 | 3 | 7 | 2 |
| 11 | 양상추 | 1 | 9 | 2 |
| 12 | 견과류 | 3 | 6 | 1 |
| 13 | 배 | 10 | 7 | 0 |
| 14 | 새우 | 2 | 3 | 1 |
data = fresh.iloc[:, 1:3]
target = fresh['class']
X_train, X_test, y_train, y_test = \
train_test_split(data, target, train_size=0.7,
stratify=target, random_state=2211211235)# criterion: 정보 혼잡도 알고리즘 지정
rfclf = RandomForestClassifier(n_estimators=100, n_jobs=-1,
oob_score=True, criterion='entropy')
rfclf.fit(X_train, y_train)RandomForestClassifier(criterion='entropy', n_jobs=-1, oob_score=True)On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestClassifier(criterion='entropy', n_jobs=-1, oob_score=True)rfclf.oob_score_1.0pred = rfclf.predict(X_test)
accuracy_score(y_test, pred)0.8rfclf.feature_importances_array([0.50857991, 0.49142009])
plot_decision_regions(data.to_numpy(),
target.to_numpy(), rfclf)/opt/miniconda3/lib/python3.9/site-packages/sklearn/base.py:450: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names
warnings.warn(
<AxesSubplot:>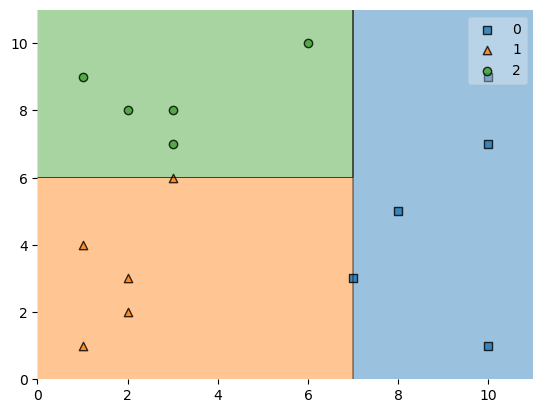
농구선수 게임데이터를 이용해서 포지션 예측
bbplayers = pd.read_csv('../data/bbplayer.csv')bbplayers.head(3)| Player | Pos | 3P | 2P | TRB | AST | STL | BLK | |
|---|---|---|---|---|---|---|---|---|
| 0 | Alex Abrines | SG | 1.4 | 0.6 | 1.3 | 0.6 | 0.5 | 0.1 |
| 1 | Steven Adams | C | 0.0 | 4.7 | 7.7 | 1.1 | 1.1 | 1.0 |
| 2 | Alexis Ajinca | C | 0.0 | 2.3 | 4.5 | 0.3 | 0.5 | 0.6 |
bbplayers['target'] = bbplayers.Pos.map({'SG': 0, 'C': 1})
bbplayers.head()| Player | Pos | 3P | 2P | TRB | AST | STL | BLK | target | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Alex Abrines | SG | 1.4 | 0.6 | 1.3 | 0.6 | 0.5 | 0.1 | 0 |
| 1 | Steven Adams | C | 0.0 | 4.7 | 7.7 | 1.1 | 1.1 | 1.0 | 1 |
| 2 | Alexis Ajinca | C | 0.0 | 2.3 | 4.5 | 0.3 | 0.5 | 0.6 | 1 |
| 3 | Chris Andersen | C | 0.0 | 0.8 | 2.6 | 0.4 | 0.4 | 0.6 | 1 |
| 4 | Will Barton | SG | 1.5 | 3.5 | 4.3 | 3.4 | 0.8 | 0.5 | 0 |
data = bbplayers.iloc[:, 2:-1]
target = bbplayers.target
X_train, X_test, y_train, y_test = \
train_test_split(data, target, train_size=0.7,
stratify=target, random_state=2211211755)# criterion: 정보 혼잡도 알고리즘 지정
rfclf = RandomForestClassifier(n_estimators=100, n_jobs=-1,
oob_score=True, criterion='entropy',
random_state=2211211755)
rfclf.fit(X_train, y_train)RandomForestClassifier(criterion='entropy', n_jobs=-1, oob_score=True, random_state=2211211755)</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-3" type="checkbox" checked><label for="sk-estimator-id-3" class="sk-toggleable__label sk-toggleable__label-arrow">RandomForestClassifier</label><div class="sk-toggleable__content"><pre>RandomForestClassifier(criterion='entropy', n_jobs=-1, oob_score=True,
random_state=2211211755)</pre></div></div></div></div></div>rfclf.oob_score_0.9714285714285714pred = rfclf.predict(X_test)
accuracy_score(y_test, pred)0.9666666666666667rfclf.feature_importances_array([0.23626094, 0.03841326, 0.18551233, 0.08823063, 0.06973086,
0.38185198])728x90
'PYTHON > 데이터분석' 카테고리의 다른 글
| [머신러닝-비지도] 01. 군집분석 (0) | 2023.01.04 |
|---|---|
| [머신러닝] 17. 부스팅(boosting) (0) | 2023.01.03 |
| [머신러닝] 15. 배깅(bagging) (0) | 2023.01.03 |
| [머신러닝] 14. 앙상블 (0) | 2023.01.03 |
| [머신러닝] 13. SVM (0) | 2023.01.03 |
'PYTHON/데이터분석' Related Articles
more




Comments